How to learn Japanese w/ Python
Takanori Suzuki

PyCon APAC 2024 / 2024 Oct
Agenda ✅
Background and Motivation / Goal
Japanese is Difficult
Python supports Japanese leaning
Background and Motivation 🏞️
Background and Motivation
Developing School Textbook Web at work
Japanese NLP to make it Easier to Learn
Python libs could help people Learn Japanese
Background and Motivation(cont.)
-
Japanese is “super-hard languages” for English speakers to learn
Mandarin, Cantonese, Korean and Arabic
Background and Motivation(cont.)

Goal
What is difficult about Japanese
How to use Japanese NLP libs and APIs
Python could support learning Japanese
Photos 📷 Share 🐦 👍
#pyconapac / @takanory
slides.takanory.net 💻
Who am I? 👤
Takanori Suzuki / 鈴木 たかのり ( @takanory)
PyCon JP Association: Chair
BeProud Inc.: Director / Python Climber
Python Boot Camp, Python mini Hack-a-thon, Python Bouldering Club
Love: Ferrets, LEGO, 🍺 / Hobby: 🎺, 🧗♀️


PyCon JP Association
Nonprofit organization for Python users in Japan, to promote Python and supports its development. Further it is our goal to hold an annual PyCon JP.
![]()
PyCon JP 2025
Date: 2025 Sep 26(Fri)-27(Sat)
Place: Hiroshima, Japan
There are English talks

Hiroshima? ⛩️
Fukushima - Hiroshima - Kyoto - Tokyo - Hokkaido
Direct flights to Hiroshima - HIJ, Japan
Seoul, Taipei, Shanghai, Hong Kong, Dalian, Hanoi
Questions 🙋♂️
Have you learned Japanese? 🙋♀️
Are you interested in Japanese? 🙋♂️
Would you like to visit Japan? 🙋♀️ 🙋♂️
PyCon JP 2025
Date: 2025 Sep 26(Fri)-27(Sat)
Place: Hiroshima, Japan
There are English talks
Japanese is Difficult 😫
3 Types of Characters
No Spaces between Words
Multiple Readings of Kanji
3 Types of Characters
English |
Snake |
Beer |
|---|---|---|
Pronounciation |
hebi |
biːru |
Hiragana |
へび |
びーる |
Katakana |
ヘビ |
ビール |
Kanji |
蛇 |
麦酒 |
No Spaces between Words
すもももももももものうち
No Spaces between Words
すもももももももものうち
↓
すもも/も/もも/も/もも/の/うち
“Plums and peaches are part of peaches”
Multiple Readings of Kanji
日: day, sun
Multiple Readings of Kanji
2 styles of readings
Japanese-style reading(訓読み)
Chinese-style reading(音読み)
Multiple Readings of Kanji
日: day, sun
Japanese-style reading: にち(nichi)、ひ(hi)
Chinese-style reading: じつ(jitsu)、か(ka)
Multiple Readings of Kanji
Japanese-style reading: にち(nichi)、ひ(hi)
Chinese-style reading: じつ(jitsu)、か(ka)
How to read?
日曜日 (Sunday)
前日 (Previous day)
Multiple Readings of Kanji
日曜日 (Sunday)
Japanese-style reading: にち(nichi)、ひ(hi)
前日 (Previous day)
Chinese-style reading: じつ(jitsu)、か(ka)
Japanese is Difficult!! 😱
Python supports Japanese leaning
<ruby> HTML Tag 💎
What is Ruby ?
ルビ characters are small annotation
Usually placed above the text
(Not a Programming Language)
<ruby> HTML Tag 💎
<ruby>represents small annotations<rt>specifies the ruby text component
PyCon APAC 2024
<ruby>PyCon<rt>Python Conference</rt></ruby>
<ruby>APAC<rt>Asia Pacific</rt></ruby>
2024
Indicate pronunciation with <ruby>
Alphabet annotation: Pronounciation
パイコン えいぱっく (PyCon APAc)
<ruby>パイコン<rt>pa i ko n</rt></ruby>
<ruby>えいぱっく<rt>e i pa kku</rt></ruby>
Indicate pronunciation with <ruby>
Hiragana annotation: Readings
ふりがな
インドネシア 共和国 (Republic of Indonesia)
<ruby>インドネシア<rt>いんどねしあ</rt></ruby>
<ruby>共和国<rt>きょうわこく</rt></ruby>
Understand <ruby> Tag 💡
Hiragana and Katakana (あ / ア)
hebi / へび / ヘビ
Hiragana and Katakana
Hiragana and Katakana are phonogram
1 character represent a phoneme(speech sound)
Like a Japanese alphabet
Hiragana: あかさたな…
Katakana: アカサタナ…
Hiragana and Katakana
Basically use Hiragana
いんどねしあ (Indonesia)
Katakana is used for foreign words
パイコン (PyCon)
Romanization of Japanese (Romaji)
Alphabet to represent Japanese
Romaji is often used on Information Sign

Learn Hiragana/Katakana using Romaji
jaconv
jaconv: interconverter for Hiragana, Katakana, alphabet and etc.
$ python3.12 -m venv env
$ . env/bin/activate
(env) pip install jaconv
>>> import jaconv
>>> jaconv.kana2alphabet("いんどねしあ") # Hiragana -> alphabet
'indoneshia'
>>> jaconv.kata2alphabet("パイコン") # Katakana -> alphabet
'paikon'
Add Romaji annotation
kana2roman.py
import sys
import jaconv
def kana2romaji(kana: str) -> str:
"""Convert Hiragana and Katakana to Romaji"""
hiragana = jaconv.kata2hira(kana) # Katakana -> Hiragana
return jaconv.kana2alphabet(hiragana) # Hiragana -> alphabet
def kana_with_romaji_ruby(kana: str) -> str:
"""Add romaji ruby to Kana text"""
romaji = kana2romaji(kana)
return f"<ruby>{kana}<rt>{romaji}</rt></ruby>"
if __name__ == "__main__":
print(kana_with_romaji_ruby(sys.argv[1]))
Add Romaji annotation
(env) $ python kana2roman.py パイコンえいぱっく
<ruby>パイコンえいぱっく<rt>paikoneipakku</rt></ruby>
パイコンえいぱっく
Can read Hiragana and Katakana 🎉
No Spaces between Words
すもももももももものうち
No Spaces between Words
Japanese has no spaces between words
Use Dictionary to Recognise words
Japanese Morphological Analyzer library required
Japanese Morphological Analyzer

Japanese Morphological Analyzer
SudachiPy: pypi.org/project/SudachiPy
SudachiDcit: pypi.org/project/SudachiDict-core
(env) $ pip install sudachipy sudachidict_core
SudachiPy
Made with Rust, Very Fast
Three Types of Dictionaries
Small: small vocabulary
Core: basic vocabulary (default)
Full: miscellaneous proper nouns
Word Segmentation
Split the words using Dictionary
>>> from sudachipy import Dictionary
>>> tokenizer = Dictionary().create()
>>> text = "すもももももももものうち"
>>> for token in tokenizer.tokenize(text):
... print(token)
...
すもも
も
もも
も
もも
の
うち
Cannot read Hiragana?
Word Segmentation with Romaji
word_segmentation.py
import sys
from sudachipy import Dictionary
from kana2roman import kana_with_romaji_ruby
tokenizer = Dictionary().create()
def word_segmentation(text: str) -> str:
result = []
for token in tokenizer.tokenize(text):
result.append(kana_with_romaji_ruby(str(token)))
return " / ".join(result)
if __name__ == "__main__":
print(word_segmentation(sys.argv[1]))
Word Segmentation with Romaji
(env) $ python word_segmentation.py すもももももももものうち
<ruby>すもも<rt>sumomo</rt></ruby> / <ruby>も<rt>mo</rt></ruby> / <ruby>もも<rt>momo</rt></ruby> / <ruby>も<rt>mo</rt></ruby> / <ruby>もも<rt>momo</rt></ruby> / <ruby>の<rt>no</rt></ruby> / <ruby>うち<rt>uchi</rt></ruby>
すもも / も / もも / も / もも / の / うち
Can split into Words 🎊
Multiple Readings of Kanji
日曜日、前日
Multiple Readings of Kanji
日: day, sun
Japanese-style reading(訓読み): にち, ひ
Chinese-style reading(音読み): じつ, か
Multiple Readings of Kanji
日 曜 日 (Sunday): にち よう び
前 日 (Previous day): ぜん じつ
😨
Multiple Readings of Kanji idioms
Same combination but different readings
一日: first day, one day
一日 目(Day 1)
一月 一日(Jan 1st)
Multiple Readings of Kanji idioms
Same combination but different readings
一日: first day, one day
一日 目(Day 1): いちにち め
一月 一日(Jan 1st): いちがつ ついたち
😱 😱
Special readings of Kanji idioms
今 日 (today)
昨 日 (yesterday)
明 日 (tomorrow)
Special readings of Kanji idioms
今 日 (today): きょう
昨 日 (yesterday): きのう
明 日 (tomorrow): あした
🤯 🤯 🤯
Get Reading of Kanji
今 日 は一月一 日 で 日 曜 日
Today is January 1st, Sunday
Get Reading of Kanji
Use SudachiPy and SudachiDict
reading_form(): Reading in Katakana
>>> from sudachipy import Dictionary
>>> tokenizer = Dictionary().create()
>>> text = "今日は一月一日で日曜日"
>>> for token in tokenizer.tokenize(text):
>>> print(token, token.reading_form())
...
今日 キョウ
は ハ
一 イチ
月 ガツ
一日 ツイタチ
で デ
日曜日 ニチヨウビ
Get Reading of Kanji
Cannot read Katakana? Use jaconv!
>>> import jaconv
>>> for token in tokenizer.tokenize(text):
... reading = token.reading_form()
... hiragana = jaconv.kata2hira(reading)
... romaji = jaconv.kata2alphabet(reading)
... print(f"{token}, {reading}, {hiragana}, {romaji}")
...
今日, キョウ, きょう, kyou
は, ハ, は, ha
一, イチ, いち, ichi
月, ガツ, がつ, gatsu
一日, ツイタチ, ついたち, tsuitachi
で, デ, で, de
日曜日, ニチヨウビ, にちようび, nichiyoubi
Add Reading to Kanji
kanji_reading.py
import sys
import jaconv
from sudachipy import Dictionary
tokenizer = Dictionary().create()
def add_reading(text: str) -> str:
"""Add Hiranaga ruby to text"""
result = ""
for token in tokenizer.tokenize(text):
ruby = jaconv.kata2hira(token.reading_form())
result += f"<ruby>{token}<rt>{ruby}</rt></ruby>\n"
return result
if __name__ == "__main__":
print(add_reading(sys.argv[1]))
Add Reading to Kanji
今日 は 一 月 一日 で 日曜日
(env) $ python kanji_reading.py 今日は一月一日で日曜日
<ruby>今日<rt>きょう</rt></ruby>
<ruby>は<rt>は</rt></ruby>
<ruby>一<rt>いち</rt></ruby>
<ruby>月<rt>がつ</rt></ruby>
<ruby>一日<rt>ついたち</rt></ruby>
<ruby>で<rt>で</rt></ruby>
<ruby>日曜日<rt>にちようび</rt></ruby>
Add Reading to Kanji
kanji_reading_romaji.py
import sys
import jaconv
from sudachipy import Dictionary
tokenizer = Dictionary().create()
def add_reading(text: str) -> str:
"""Add Romaji ruby to text"""
result = ""
for token in tokenizer.tokenize(text):
# ruby = jaconv.kata2hira(token.reading_form())
ruby = jaconv.kata2alphabet(token.reading_form())
result += f"<ruby>{token}<rt>{ruby}</rt></ruby>\n"
return result
if __name__ == "__main__":
print(add_reading(sys.argv[1]))
Add Reading to Kanji
今日 は 一 月 一日 で 日曜日
(env) $ python kanji_reading_romaji.py 今日は一月一日で日曜日
<ruby>今日<rt>kyou</rt></ruby>
<ruby>は<rt>ha</rt></ruby>
<ruby>一<rt>ichi</rt></ruby>
<ruby>月<rt>gatsu</rt></ruby>
<ruby>一日<rt>tsuitachi</rt></ruby>
<ruby>で<rt>de</rt></ruby>
<ruby>日曜日<rt>nichiyoubi</rt></ruby>
Can read Kanji 🥳
Can read but Cannnot Pronouce 🗣️
Readings and Pronounciations are slightly different
Readings: ou / ei
Pronounciaciton: oo / ee
東京 / 英語
Text to Speech
-
5 million chars free per month for 12 months
(env) $ pip install boto3
(env) $ export AWS_ACCESS_KEY_ID=AKIAYI...
(env) $ export AWS_SECRET_ACCESS_KEY=ZoWbpmi...
(env) $ export AWS_DEFAULT_REGION=ap-northeast-1
Text to Speech
text_to_speech.py
import sys
import boto3
polly = boto3.client("polly")
def text_to_speech(text: str) -> None:
result = polly.synthesize_speech(
Text=text, OutputFormat="mp3", VoiceId="Mizuki")
with open("japanese.mp3", "wb") as f:
f.write(result["AudioStream"].read())
if __name__ == "__main__":
text_to_speech(sys.argv[1])
Text to Speech
(env) $ python text_to_speech.py 東京、英語
Can pronounce Japanese 🥳🥳
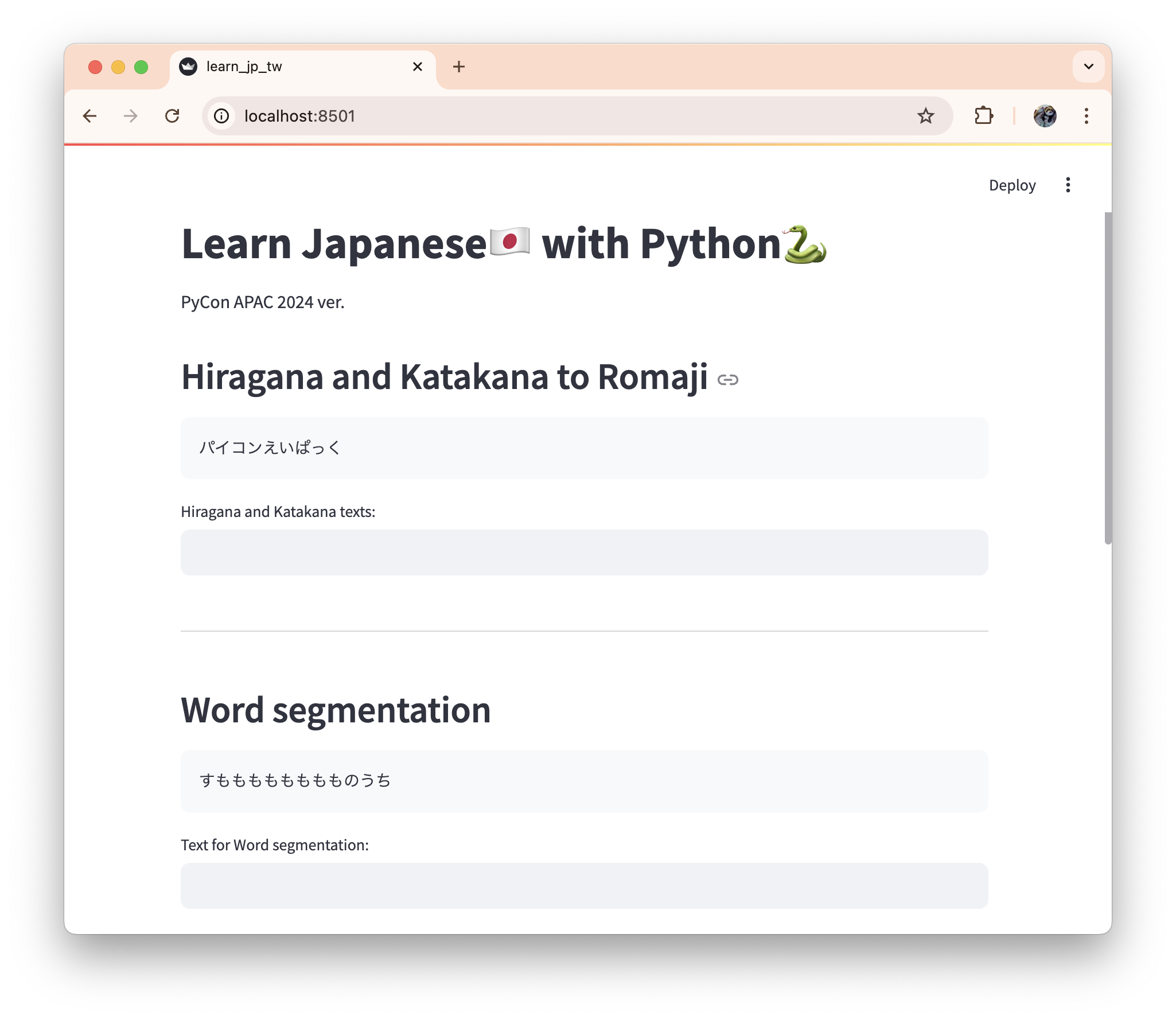
Sample App
Summary
Japanese is Difficult
3 Charcters, No spaces, Kanji readings
Python supports Japanese learning
jaconv: Interconverter
SudachiPy: Morphological analyzer
Amazon Polly: Text to Speech
🇯🇵 ❤️
Learn Japanese with Python
Thank you / Terima kasih 🙏
@takanory takanory takanory takanory